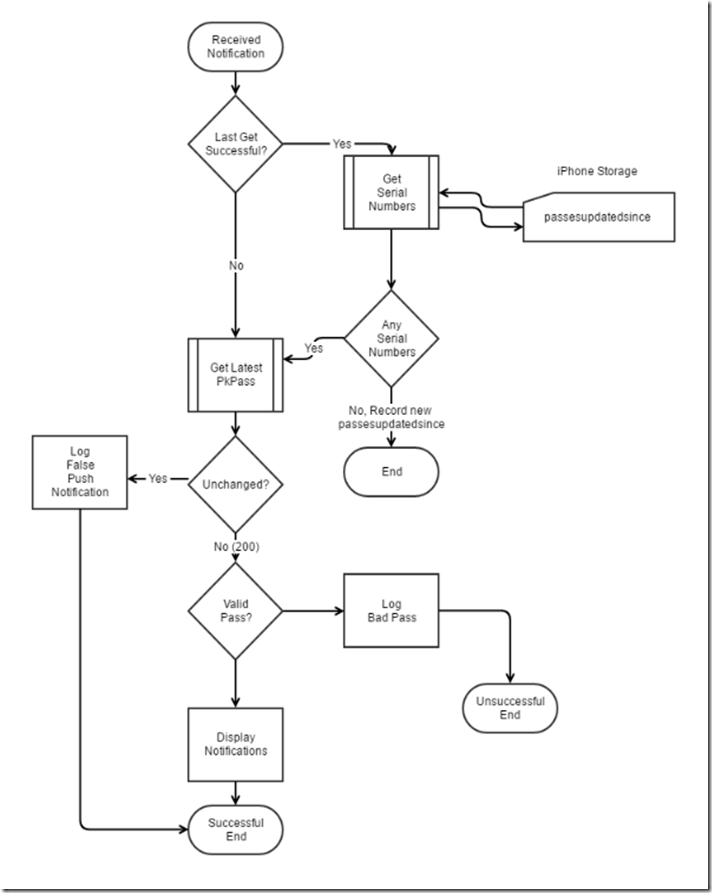
Docker for Angular 2 devs

Docker is a Virtual Environment Docker containers are great for adding new developers to existing projects, or for learning new technologies without polluting your existing developer machine/host. Docker allows you to put a fence around the environment while still using it. Why Docker for Angular 2? Docker is an easy way to get up and going on a new stack, environment, tool, or operating system without having to learn how to install and configure the new stack. A collection of docker images are available from Docker Hub ranging from simple to incredibly complex -- saving you the time and energy. Angular 2 examples frequently include a Dockerfile in the repository which makes getting the example up and running much quicker -- if you don't have to focus on package installation and configuration. The base Angular 2 development stack uses Node, TypeScript, Typings, and a build system (such as SystemJs or Webpack ). Instead of learning each stack element before/while learning...