Converting SalesForce SOQL results to a Linked Dataset for use by C#
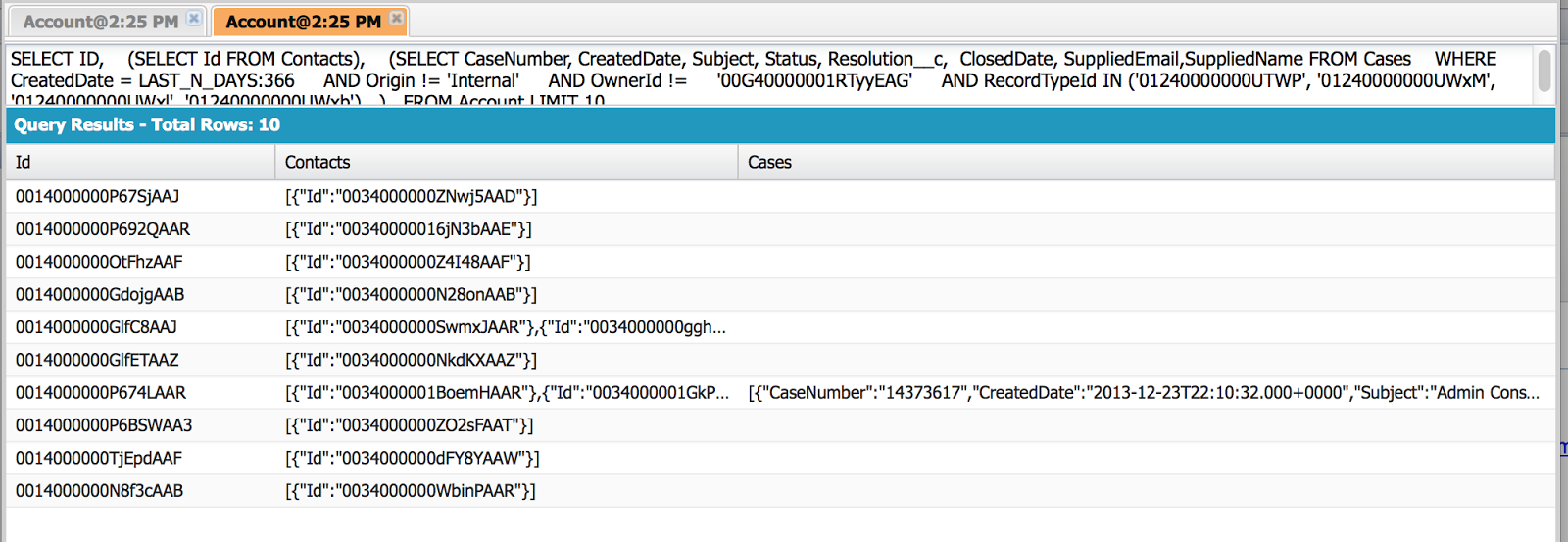
In my last post, I illustrated the 'simple' way of getting the data back - by just creating a Xml Document from the results. This is not always efficient -- in fact, I have gotten out of system memory errors on some queries. In this post I will take the same query and show a little slight of code. The query was: SELECT Name, (SELECT Name, Email FROM Contacts), (SELECT CaseNumber, CreatedDate, Subject, Status, Resolution__c, ClosedDate, SuppliedEmail,SuppliedName FROM Cases WHERE CreatedDate = LAST_N_DAYS:366 AND Origin != 'Internal' AND OwnerId != '00G40000001RTyyEAG' AND RecordTypeId IN ('01240000000UTWP', '01240000000UWxM', '01240000000UWxl', '01240000000UWxb') ) FROM Account WHERE ID IN (SELECT AccountId FROM Contact Where Email in ({0})) Extension Method to Handle SOQL Result Columns The code ...